![[Amazon Bedrock] 別アカウントのBedrockを呼び出す方法まとめ (LLM呼び出し、Knowledge Base-RAG、Kendra-RAG)](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-e3065182082062711612153bbdcf1d96/c04359de689df2f56eb066576ab63fb5/amazon-bedrock?w=3840&fm=webp)
[Amazon Bedrock] 別アカウントのBedrockを呼び出す方法まとめ (LLM呼び出し、Knowledge Base-RAG、Kendra-RAG)
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
みなさん、こんにちは!
福岡オフィスの青柳です。
何らかの理由で「アプリケーションから別アカウントのBedrockを利用したい」という場合があるかと思います。
今回は、そのような場合に必要となる設定方法について、Bedrockの利用パターン毎に解説します。
※ 今回の記事では、Bedrockを呼び出すアプリケーションとしてLambda関数を例にして解説しています。EC2やコンテナの場合には適宜読み替えて頂く必要がありますが、大きな考え方は変わりません。
Case 1: 別アカウントのBedrockのLLMを呼び出す
まずは最もシンプルなパターンから。
アプリケーション本体は「メインAWSアカウント」で動作しており、Bedrockのみ別アカウントを利用したいという要件です。
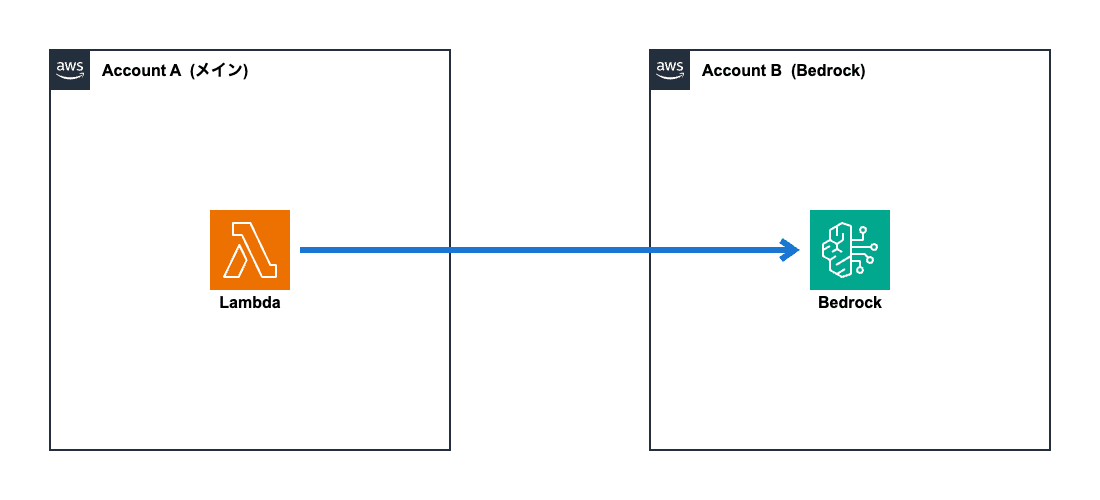
このような場合には、IAM (正確にはAWS STSサービス) の「AssumeRole」の仕組みを用います。
BedrockなどAWSの多くのサービスは、直接的には、自分のアカウント内にある「IAMユーザー」「IAMロール」からのアクセスしか受け付けないようになっています。
(例外は、S3のように「リソースベースポリシー」の設定が可能な一部のサービスです)
それでも、別のアカウントのIAMユーザー/IAMロールからサービスを利用したい場合があります。
その場合は、サービスへのアクセス権限を持たせた「一時クレデンシャル」を払い出してもらうことにより、アクセスを可能にします。
これを実現する機能 (サービス) が「AWS STS」(AWS Security Token Service) であり、一時クレデンシャルを要求するアクションが「AssumeRole」です。
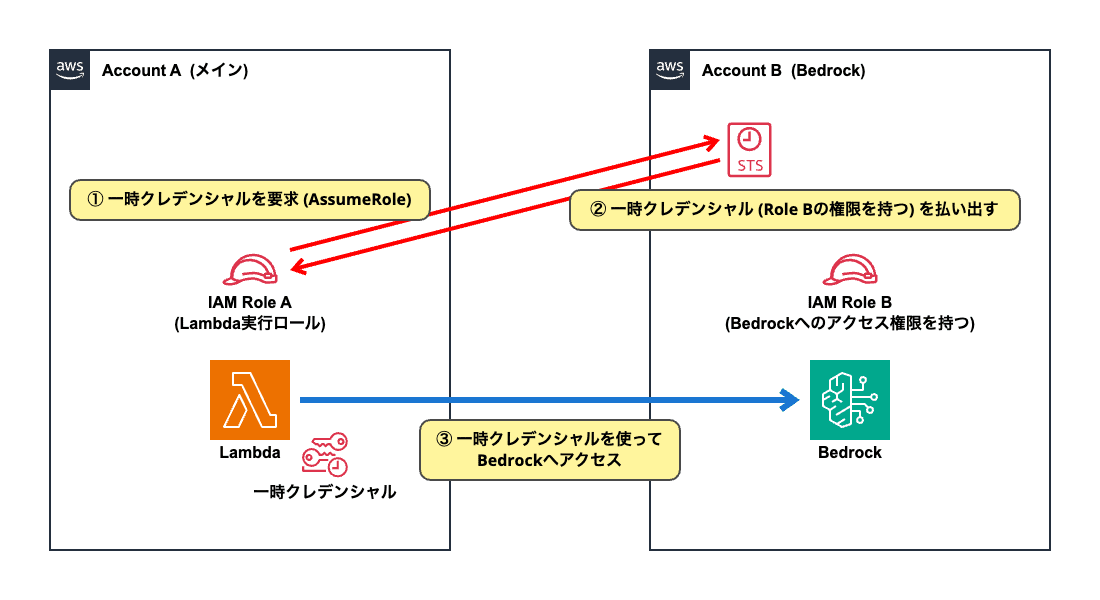
AssumeRoleを使って「Account A」のLambda関数が「Account B」のBedrockへアクセスする流れは、以下の通りです:
- (1) 「IAM Role A」の権限で実行されるLambda関数のコード内で、「Account B」の「IAM Role B」を指定して「AsumeRole」を実行する
- (2) AWS STSサービスから「IAM Role B」の権限を持った一時クレデンシャルが払い出される
- (3) Lambda関数のコード内で一時クレデンシャルを使って、「Account B」のBedrockサービスに対して操作を行う
必要な設定を順に説明します。
Account B (Bedrock用アカウント) の設定
Bedrockモデルアクセスの有効化
利用予定のBedrock「基盤モデル」を有効化しておきます。
(手順は、クロスアカウントではないBedrock利用の場合と変わりません)
IAMロールの作成 (Role B)
信頼ポリシーを以下のように設定します。
これにより、「Account A」の「IAM Role A」が「IAM Role B」を指定してAssumeRoleを要求した際に、要求を受け付けるようになります。(このポリシーが無いとAssumeRoleの要求は拒否されます)
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::{{AccountId_A}}:role/{{Role_A}}"
},
"Action": "sts:AssumeRole"
}
]
}
許可ポリシーを以下のように設定します。
「IAM Role B」がBedrockの基盤モデルを呼び出せるように権限を与えます。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "bedrock:InvokeModel",
"Resource": [
"arn:aws:bedrock:{{Region}}::foundation-model/{{ModelId}}"
]
}
]
}
「Resource」にはBedrock基盤モデルのARNを指定します。
以下のような指定方法があります:
- 任意のリージョンの任意のモデルを許可:
arn:aws:bedrock:*::foundation-model/* - 特定リージョンの任意のモデルを許可:
arn:aws:bedrock:ap-northeast-1::foundation-model/* - 特定リージョンの特定モデルを許可:
arn:aws:bedrock:ap-northeast-1::foundation-model/anthropic.claude-3-5-sonnet-20240620-v1:0
なお、「任意のリージョン」「任意のモデル」の許可を与えた場合でも、該当する基盤モデルを有効化していなれければ、当然ながら利用はできません。
Account A (メインアカウント) の設定
IAMロールの作成 (Role A)
信頼ポリシーを以下のように設定します。
Lambda関数にアタッチするIAMロールとして必要な設定です。(クロスアカウントとは直接関係ない)
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
許可ポリシーを以下のように設定します。
このIAMロールが「Account B」の「IAM Role B」を指定してAssumeRoleを行うことを許可するものです。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "arn:aws:iam::{{AccountId_B}}:role/{{Role_B}}"
}
]
}
「Account B」での手順で「IAM Role B」に信頼ポリシーを設定しましたが、そちらは「AssumeRoleを受ける側がAssumeRoleを実行する側に対して許可を与える」ためのものでした。
一方、こちらの許可ポリシーは、純粋に「IAM Role A」が何を行えるのかを定義するものです。
なお、このポリシー設定に加えて、Lambda実行ロールで一般的に必要なポリシーをアタッチしておくと良いでしょう。
(例えば「AWSLambdaBasicExecutionRole」AWS管理ポリシーなど)
Lambda関数の作成
Lambda関数を作成します。
実行ロールとして、上の手順で作成した「IAM Role A」を割り当てます。
以下はAWS SDK for Python (boto3) によるコードのサンプルです:
import boto3
import json
TARGET_ROLE_ARN='arn:aws:iam::{{AccountId_B}}:role/{{Role_B}}'
def get_session(role_arn, role_session_name):
sts_client = boto3.client('sts')
assumed_role = sts_client.assume_role(
RoleArn=role_arn,
RoleSessionName=role_session_name,
)
session = boto3.session.Session(
aws_access_key_id=assumed_role['Credentials']['AccessKeyId'],
aws_secret_access_key=assumed_role['Credentials']['SecretAccessKey'],
aws_session_token=assumed_role['Credentials']['SessionToken'],
)
return session
def lambda_handler(event, context):
session = get_session(TARGET_ROLE_ARN, 'assume-role-session')
bedrock_client = session.client('bedrock-runtime', region_name='ap-northeast-1')
prompt = '著名なクリスマスソングを3曲挙げてください'
response = bedrock_client.converse(
modelId='anthropic.claude-3-haiku-20240307-v1:0',
messages=[{
'role': 'user',
'content': [{'text': prompt}],
}],
inferenceConfig={'maxTokens': 1000},
)
print(response['output']['message']['content'][0]['text'])
関数「get_session()」が今回の処理のポイントです。
まず、AssumeRoleを使って「IAM Role B」を指定した一時クレデンシャルを取得します。
次に、取得したクレデンシャルを使ってboto3のSessionオブジェクトを作成しています。
メイン処理では、このセッションを使って「bedrock-runtime」のClientオブジェクトを生成し、「converse()」メソッドを実行しています。
これにより、「Account A」のLambda関数から「Account B」のBedrockに対してLLMの呼び出しが実現できました。
なお、Sessionオブジェクトを使わずに、Clientオブジェクトに直接クレデンシャルを与える方法もありますが、今回はセッションを使っています。
セッションを取得している箇所を以下のように書き換えると、クロスアカウントではなく自アカウントに閉じたBedrock呼び出しを行うようになります。
(「IAM Role A」に自アカウントのBedrockを呼び出す権限を付与する必要があります)
session = get_session(TARGET_ROLE_ARN, 'assume-role-session')
↓
session = boto3.session.Session()
Lambda関数から別アカウントのBedrockを呼び出す方法については、下記ブログ記事に具体的な手順が説明されています。併せて確認してみてください。
Case 2: 別アカウントに作成したBedrockナレッジベースを使ってRAGを実行する
次のパターンは、別アカウントのBedrockの「ナレッジベース」を使ってRAGを実行したいという要件です。
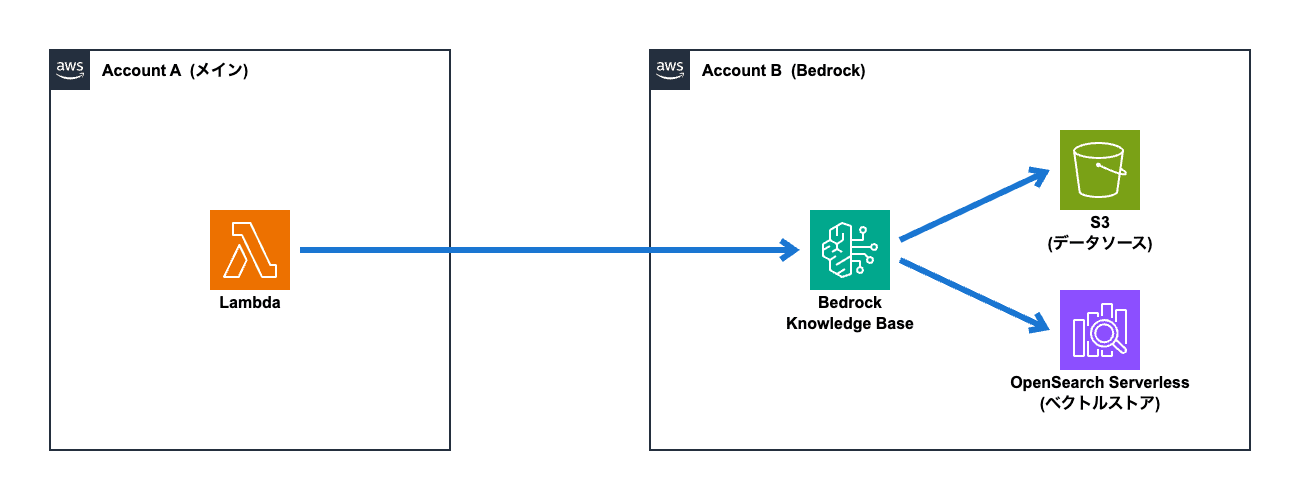
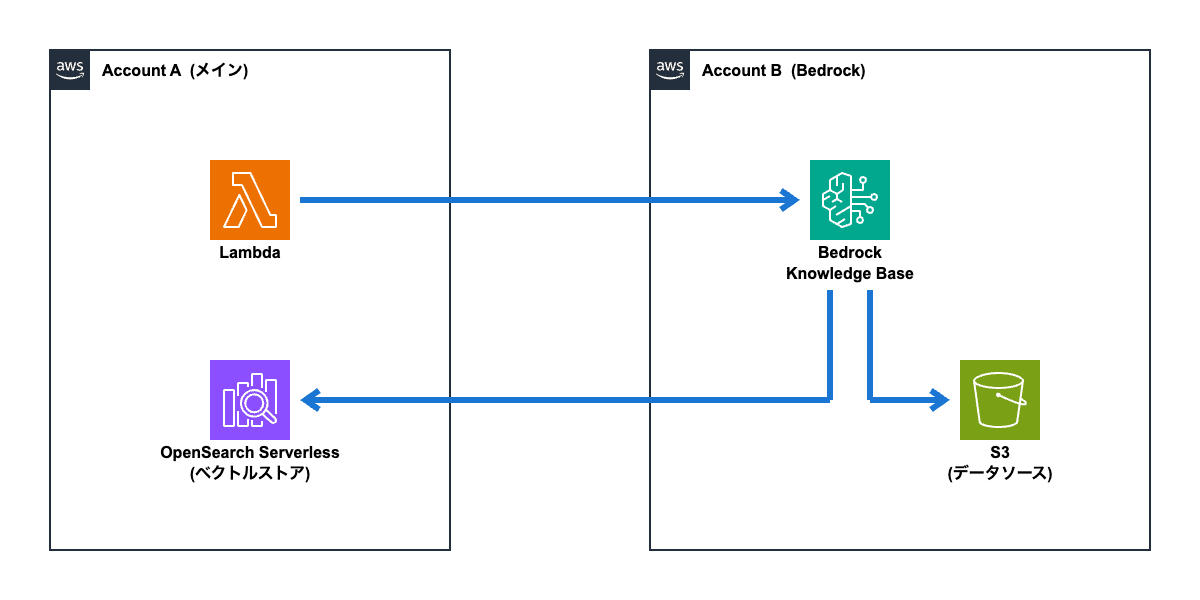
Bedrockナレッジベースを利用する場合、Bedrockに加えて「データソース」と「ベクトルストア」のリソースが必要となります。
マネジメントコンソールからナレッジベースを作成すると、デフォルト設定では「データソース」(S3) はBedrockと同じAWSアカウント上のリソースを参照し、「ベクトルストア」(OpenSearch Serverless) はBedrockと同じAWSアカウント上にリソースを作成します。
このパターンでは、それらのリソースをそのまま使う前提です。
この場合、「Case 1」のパターンと同様に「AssumeRole」の仕組みを使って、Lambda関数が別アカウントのBedrockナレッジベースへアクセスすることになります。
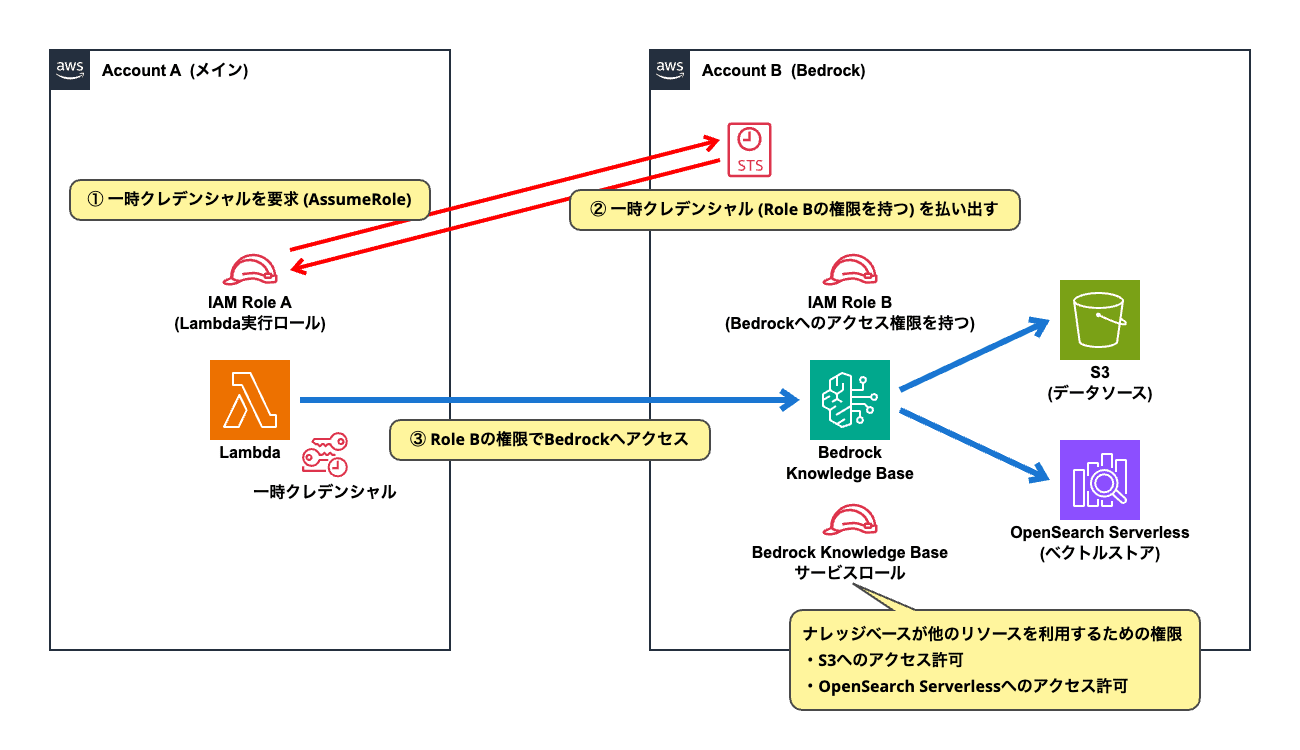
ナレッジベースがデータソース (S3) やベクトルストア (OpenSearch Serverless) へアクセスするための権限は、専用のIAMロール「Bedrock Knowledge Baseサービスロール」で設定します。
Account B (Bedrock用アカウント) の設定
ナレッジベースの作成
マネジメントコンソールからナレッジベースを作成する場合、「データソース」(S3) の選択はデフォルトの「このAWSアカウント」を選択します。

「ベクトルストア」(OpenSearch Serverless) は「新しいベクトルストアをクイック作成」を選択すると、自動的にナレッジベースと同じAWSアカウント上にリソースが作成されます。
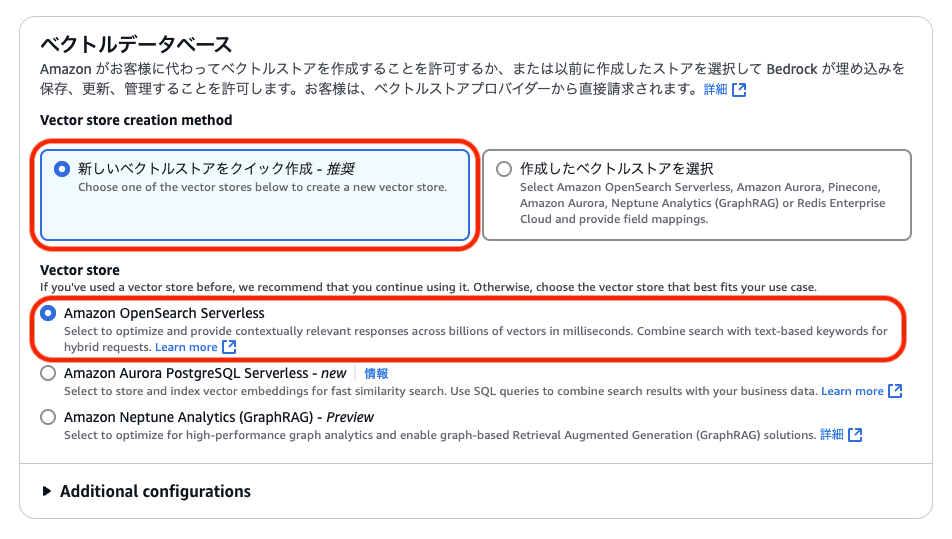
IAMロールの作成 (Role B)
信頼ポリシーを以下のように設定します。
「Case 1」と同様に、「Account A」の「IAM Role A」からのAssumeRole要求を受け付けるための記述をします。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::{{AccountId_A}}:role/{{Role_A}}"
},
"Action": "sts:AssumeRole"
}
]
}
許可ポリシーを以下のように設定します。
ここでは2つの権限を記述します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"bedrock:RetrieveAndGenerate",
"bedrock:Retrieve"
],
"Resource": [
"arn:aws:bedrock:{{Region}}:{{AccountId_B}}:knowledge-base/{{KnowledgeBaseId}}"
]
},
{
"Effect": "Allow",
"Action": "bedrock:InvokeModel",
"Resource": [
"arn:aws:bedrock:{{Region}}::foundation-model/{{ModelId}}"
]
}
]
}
1つ目は、作成したナレッジベースを呼び出すことを許可する記述です。
アクションには、RAGの「Retrieve (検索)」と「Generate (回答生成)」を一気通貫で行う「bedrock:RetrieveAndGenerate」と、Retrieveのみを行う「bedrock:Retrieve」があります。
(使用する方のみ記述すれば問題ありません)
「{{KnowledgeBaseId}}」にはナレッジベースIDを指定します。(厳密さを要求しないのであれば「*」でも構いません)
2つ目は、ナレッジベースの「RetrieveAndGenerate」APIを通して基盤モデルを呼び出すことを可能にするための権限を記述します。
アクションは、RAGを使わずにBedrockのモデルを呼び出す場合と同じく「bedrock:InvokeModel」を指定します。
「{{ModelId}}」には使用する予定の基盤モデルの「モデルID」を指定します。(こちらも厳密さを要求しないのであれば「*」で構いません)
Bedrock Knowledge Baseサービスロールの作成
「Knowledge Baseサービスロール」とはIAMロールの一種で、ナレッジベースがデータソース (S3) やベクトルストア (OpenSearch Serverless) へアクセスするために必要な権限を定義するものです。
マネジメントコンソールからナレッジベースを作成する場合は自動的に作成されますが、もしCLIやIaCで作成する場合は以下のように設定してください。
信頼ポリシーを以下のように設定します。
BedrockサービスがこのIAMロールを使用できるように権限を与える設定が記述されています。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "bedrock.amazonaws.com"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"aws:SourceAccount": "{{AccountId_B}}"
},
"ArnLike": {
"aws:SourceArn": "arn:aws:bedrock:{{Region}}:{{AccountId_B}}:knowledge-base/{{KnowledgeBaseId}}"
}
}
}
]
}
「Condition」の記述が無くても動作はしますが、権限を与える範囲を厳密にするために、記述することが推奨されています。
また、マネジメントコンソールから作成した場合に自動的に作成されるサービスロールでは「{{KnowledgeBaseId}}」の部分が「*」(ワイルドカード) となっていますが、ここは具体的なナレッジベースIDを指定することが推奨されています。(ナレッジベースの作成後に書き換える)
許可ポリシーは以下のように設定します。
マネジメントコンソールで自動的に作成されるサービスロールでは、許可ポリシーは以下のように3つに分かれて作成されます。
(CLIやIaCで作成する場合は、1つにまとめてしまっても問題ありません)
1つ目の許可ポリシーは、ナレッジベースが「埋め込みモデル」を使用するための権限を記述したポリシーです。
(自動的に作成されるポリシーは AmazonBedrockFoundationModelPolicyForKnowledgeBase_XXXXX という名前になります)
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "BedrockInvokeModelStatement",
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel"
],
"Resource": [
"arn:aws:bedrock:{{Region}}::foundation-model/{{ModelId}}"
]
}
]
}
「{{ModelId}}」には、ナレッジベースで使用する埋め込みモデルのID (例:amazon.titan-embed-text-v1) を指定します。
2つ目の許可ポリシーは、ナレッジベースがデータソースへアクセスするための権限を記述したポリシーです。
(自動的に作成されるポリシーは AmazonBedrockS3PolicyForKnowledgeBase_XXXXX という名前になります)
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::{{S3BucketName}}"
],
"Condition": {
"StringEquals": {
"aws:ResourceAccount": [
"{{AccountId_B}}"
]
}
}
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::{{S3BucketName}}/{{Prefix}}/*"
],
"Condition": {
"StringEquals": {
"aws:ResourceAccount": [
"{{AccountId_B}}"
]
}
}
}
]
}
3つ目の許可ポリシーは、ナレッジベースがベクトルストアへアクセスするための権限を記述したポリシーです。
(自動的に作成されるポリシーは AmazonBedrockOSSPolicyForKnowledgeBase_XXXXX という名前になります)
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"aoss:APIAccessAll"
],
"Resource": [
"arn:aws:aoss:{{Region}}:{{AccountId_B}}:collection/{{OpenSearchServerlessCollectionId}}"
]
}
]
}
「Resource」には、ナレッジベース (OpenSearch Serverless) のARNを指定します。
Account A (メインアカウント) の設定
IAMロールの作成 (Role A)
信頼ポリシーを以下のように設定します。
「Case 1」と同様です。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
許可ポリシーを以下のように設定します。
これも「Case 1」と同様です。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "arn:aws:iam::{{AccountId_B}}:role/{{Role_B}}"
}
]
}
Lambda関数の作成
Lambda関数を作成します。
実行ロールとして、上の手順で作成した「IAM Role A」を割り当てます。
以下はAWS SDK for Python (boto3) によるコードのサンプルです:
import boto3
import json
TARGET_ROLE_ARN='arn:aws:iam::{{AccountId_B}}:role/{{Role_B}}'
KNOWLEDGEBASE_ID='{{KnowledgeBaseId}}'
def get_session(role_arn, role_session_name):
sts_client = boto3.client('sts')
assumed_role = sts_client.assume_role(
RoleArn=role_arn,
RoleSessionName=role_session_name,
)
session = boto3.session.Session(
aws_access_key_id=assumed_role['Credentials']['AccessKeyId'],
aws_secret_access_key=assumed_role['Credentials']['SecretAccessKey'],
aws_session_token=assumed_role['Credentials']['SessionToken'],
)
return session
def lambda_handler(event, context):
session = get_session(TARGET_ROLE_ARN, 'assume-role-session')
bedrock_agent_client = session.client('bedrock-agent-runtime', region_name='ap-northeast-1')
prompt = 'Bedrockナレッジベースではどのようなベクトルストアをサポートしていますか?'
response = bedrock_agent_client.retrieve_and_generate(
input={'text': prompt},
retrieveAndGenerateConfiguration={
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
'knowledgeBaseId': KNOWLEDGEBASE_ID,
'modelArn': 'arn:aws:bedrock:ap-northeast-1::foundation-model/anthropic.claude-3-haiku-20240307-v1:0',
},
},
)
print(response['output']['text'])
関数「get_session()」の処理は「Case 1」と変わりません。
ナレッジベースでは「bedrock-runtime」の代わりに「bedrock-agent-runtime」を用いますが、考え方は同様です。
これで、「Account A」のLambda関数から「Account B」のBedrockに対してナレッジベースの呼び出しが実現できました。
Case 2-A: 別アカウントに作成したBedrockナレッジベースを使ってRAGを実行する (データソースはメインアカウントを利用したい)
「Case 2」から派生するパターンとして、「Bedrockナレッジベースは別アカウントのものを使うが、データソースはメインアカウントに置きたい」というものが考えられます。
メインアカウント上で他のシステムが稼働しており、そこからデータを参照したいという要件は多いのではないかと思います。
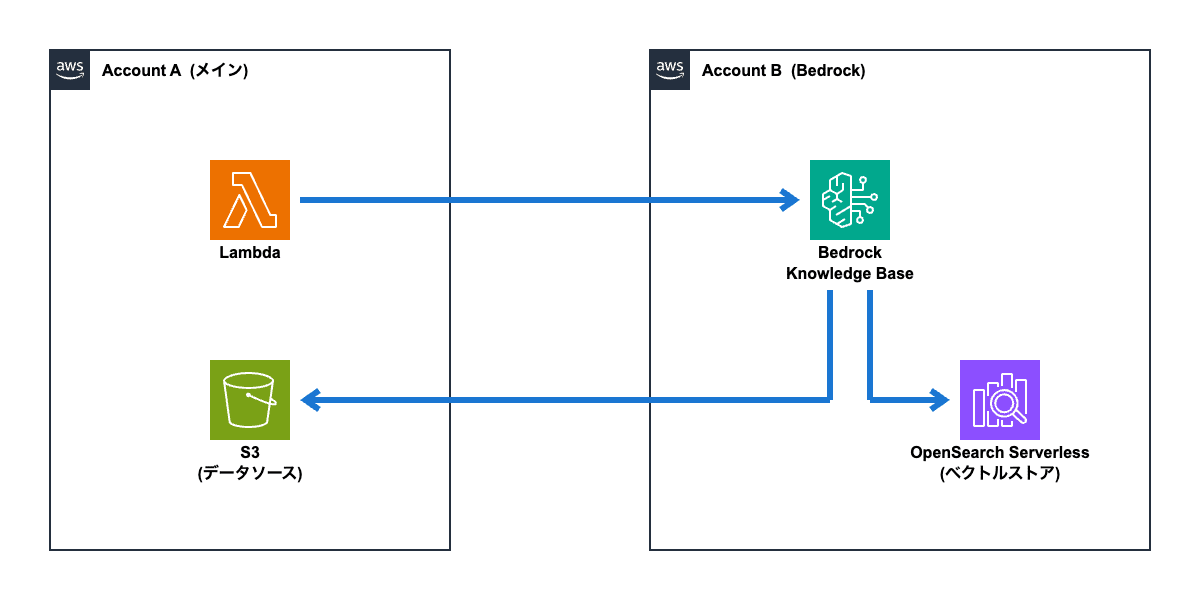
このパターンの場合、「Case 2」のパターンとの違いは「Bedrockナレッジベースがアカウントを跨いでS3バケットへアクセスする必要がある」という点です。
これを実現するためには、「Knowledge Baseサービスロール」の設定変更と、新たに「S3バケットポリシー」の設定が必要になります。
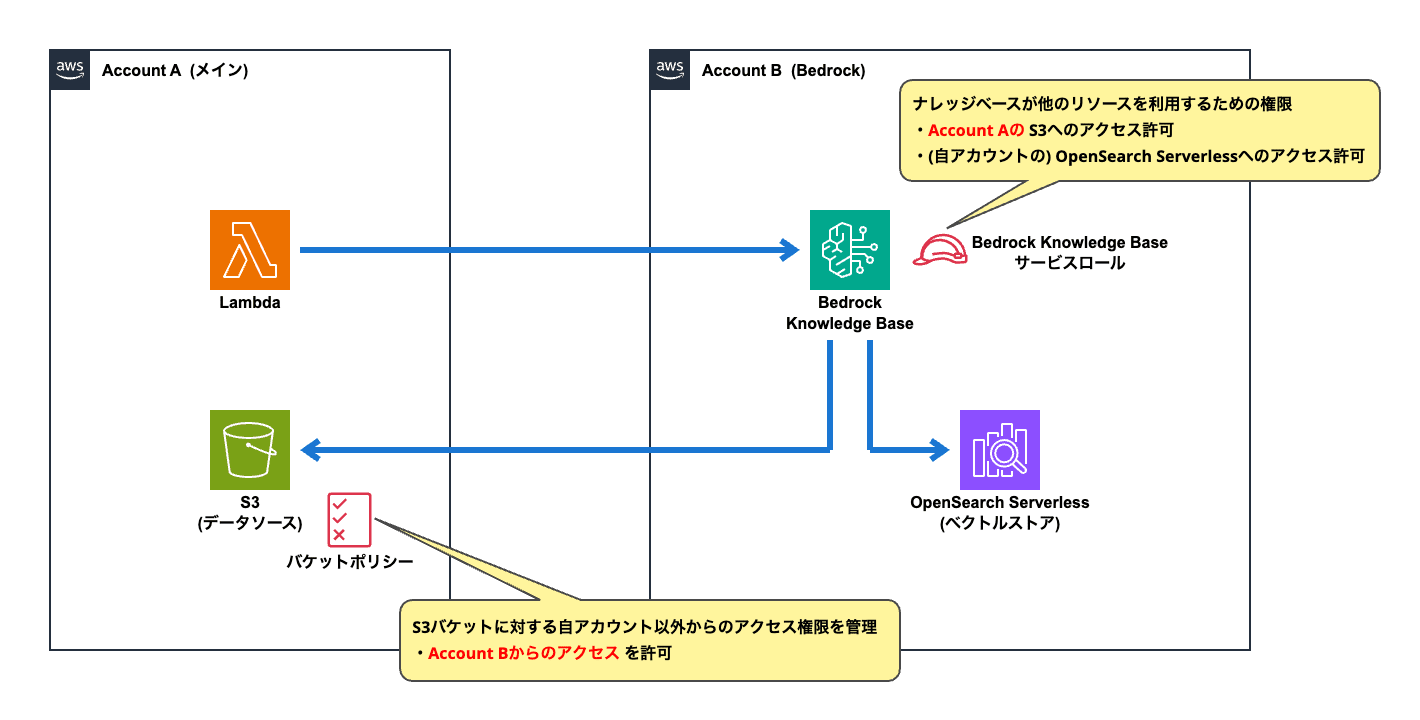
クロスアカウントでS3へアクセスを行う際は、「アクセス元」と「アクセス先」の双方でアクセス許可の設定を行う必要があります。
- アクセス元: アイデンティティベースポリシーの設定
- Knowledge Baseサービスロールの許可ポリシーで「別アカウント (Account A) のS3バケット」に対するアクセス許可の設定を行います。
- アクセス先: リソースベースポリシーの設定
- S3バケットの「バケットポリシー」で、「別アカウント (Account B) のIAMロール」からのアクセス許可の設定を行います。
必要な設定を行なっていきましょう。
「Case 2」から設定が変わらないもの
このパターンの設定は、「Case 2」つまりナレッジベースとデータストアが同じアカウント上に存在するパターンの場合と比べて、設定の多くの箇所が同じです。
具体的には、以下の設定については「Case 2」の解説の通りに設定すればOKです。
- Account A (メインアカウント) の設定
- IAMロールの作成 (Role A)
- Lambda関数の作成
- Account B (Bedrock用アカウント) の設定
- IAMロールの作成 (Role B)
- Knowledge Baseサービスロールの作成
- 信頼ポリシー
- 許可ポリシー
- 埋め込みモデルへのアクセス許可 (
AmazonBedrockFoundationModelPolicyForKnowledgeBase_XXXXX) - ベクトルストアへのアクセス許可 (
AmazonBedrockOSSPolicyForKnowledgeBase_XXXXX)
- 埋め込みモデルへのアクセス許可 (
「Case 2」から設定が変わるもの
以下の設定については「Case 2」から設定内容が変わる、もしくは、新たに設定が必要になります。
具体的な設定内容はこの後に解説します。
- Account A (メインアカウント) の設定
- S3バケットポリシーの設定
- Account B (Bedrock用アカウント) の設定
- ナレッジベースの作成
- データソースの指定時に「別のアカウント」を選択する
- Knowledge Baseサービスロールの作成
- 許可ポリシー
- データストアへのアクセス許可 (
AmazonBedrockS3PolicyForKnowledgeBase_XXXXX)
- データストアへのアクセス許可 (
- 許可ポリシー
- ナレッジベースの作成
Account B (Bedrock用アカウント) の設定
ナレッジベースの作成
マネジメントコンソールからナレッジベースを作成する場合、「データソース」(S3) の選択で「その他のAWSアカウント」を選択します。
そして、AWSアカウントIDとS3のURIを指定します。
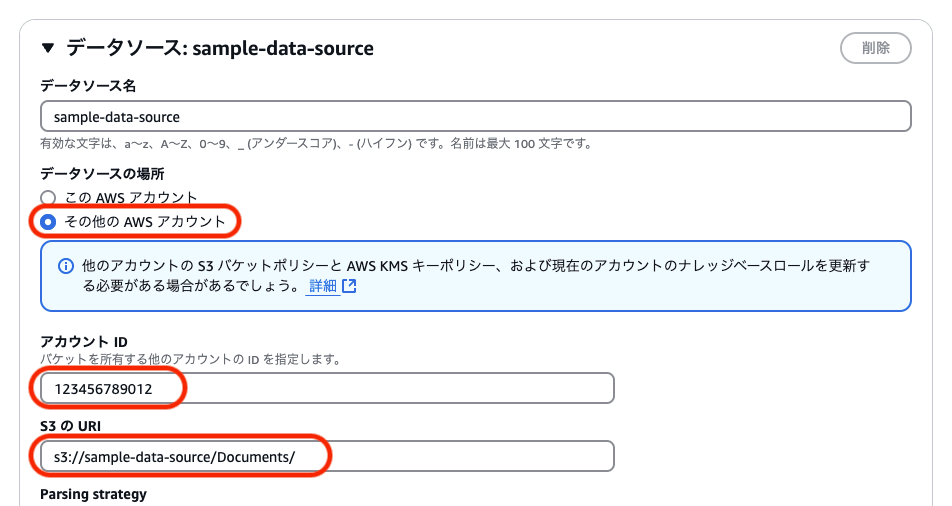
Bedrock Knowledge Baseサービスロールの作成
マネジメントコンソールからナレッジベースを作成する場合はクロスアカウントアクセスを反映したポリシーが自動的に設定されますが、もしCLIやIaCで作成する場合は以下の箇所を「Case 2」から変更してください。
許可ポリシーのうち「ナレッジベースがデータソースへアクセスするための権限を記述したポリシー」(AmazonBedrockS3PolicyForKnowledgeBase_XXXXX) を以下のように設定します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "S3ListBucketStatement",
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::{{S3BucketName}}"
],
"Condition": {
"StringEquals": {
"aws:ResourceAccount": [
"{{AccountId_A}}"
]
}
}
},
{
"Sid": "S3GetObjectStatement",
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::{{S3BucketName}}/{{Prefix}}/*"
],
"Condition": {
"StringEquals": {
"aws:ResourceAccount": [
"{{AccountId_A}}"
]
}
}
}
]
}
2箇所ある「aws:ResourceAccount」の指定を「Account A」にする必要があります。
Account A (メインアカウント) の設定
S3バケットポリシーの設定
対象のS3バケットの画面を開いて、「アクセス許可」タブ → バケットポリシー → 「編集」の操作で、バケットポリシーの編集が可能です。
(初期状態ではバケットポリシーが未設定となっています)
以下のJSONの「{{...}}」部分をご自身の環境に読み替えて、設定してください。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::{{AccountId_B}}:role/service-role/{{KnowledgeBaseRole}}"
},
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::{{BucketName}}"
]
},
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::{{AccountId_B}}:role/service-role/{{KnowledgeBaseRole}}"
},
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::{{S3BucketName}}/{{Prefix}}/*"
]
}
]
}
これらの設定を行うことにより、「アプリケーションとデータソースはメインアカウント」「Bedrockとベクトルストアは別アカウント」の構成を実現することができました。
Case 2-B: 別アカウントに作成したBedrockナレッジベースを使ってRAGを実行する (ベクトルストアはメインアカウントを利用したい)
「Case 2」の派生パターンとして、今度は「Bedrockナレッジベースは別アカウントのものを使うが、ベクトルストアはメインアカウントに置きたい」という場合を考えましょう。
結論から言いますと、このパターンは実現することができません。
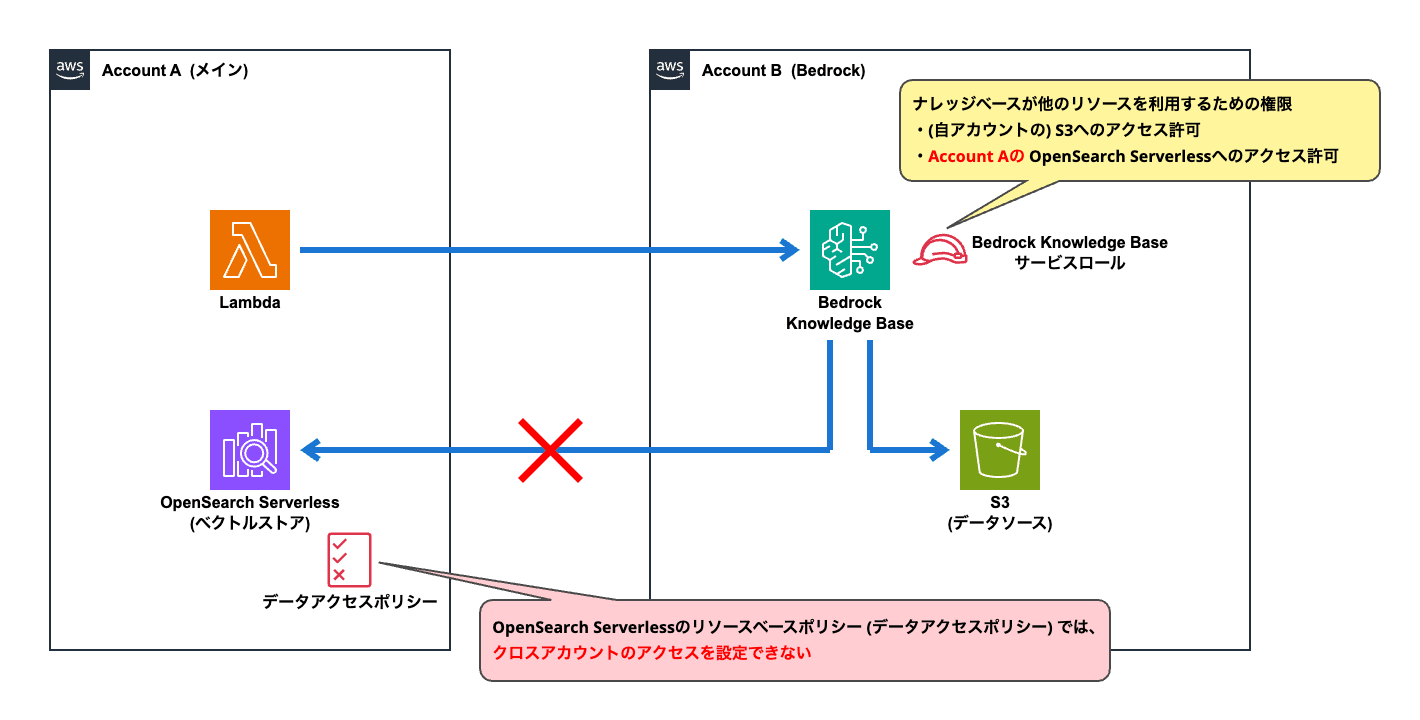
OpenSearch Serverlessには「データアクセスポリシー」と呼ばれるリソースベースポリシーが設定できるのですが、S3のバケットポリシーとは違い、クロスアカウントのアクセス許可を設定することができないのです。
したがって、ナレッジベースのベクトルストアにOpenSearch Serverlessを採用する場合は、BedrockとOpenSearch Serverlessは同一AWSアカウント上に存在する必要があり、アカウントを別々にすることはできません。
(Aurora PostgreSQL Serverlessなど他のベクトルストアを使用する場合には、また話が変わってきます)
Case 3: Kendraと別アカウントのBedrockを使ってRAGを実行する
最後に、Bedrockナレッジベース以外でRAGを実現する手段として「Amazon Kendra」を利用するパターンを見てみます。
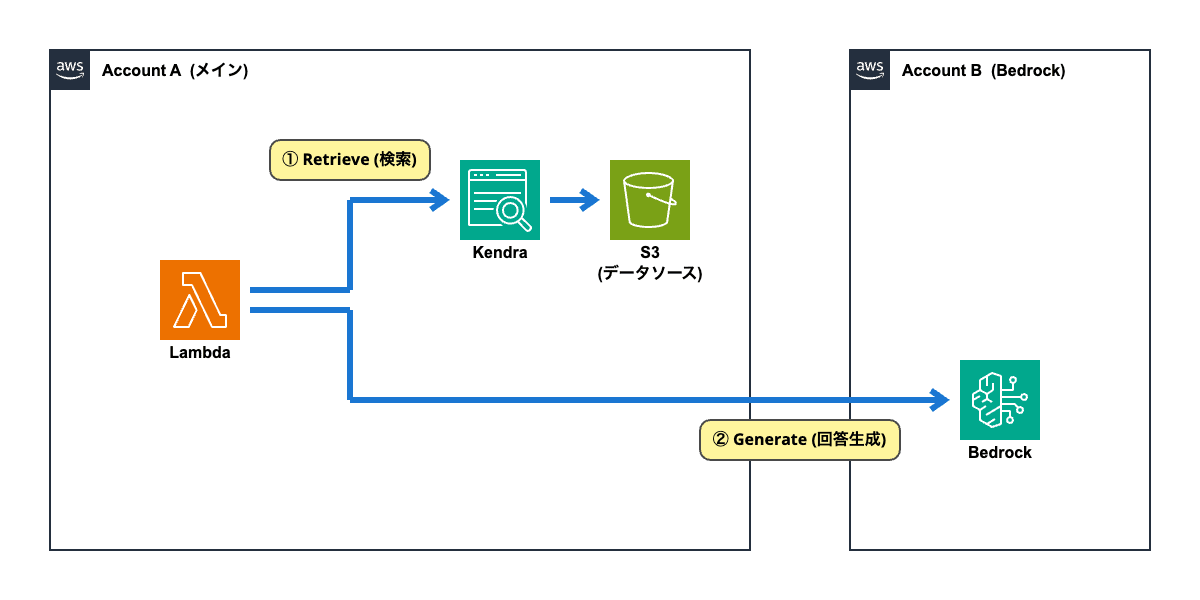
アプリケーション、Kendra、データソースがメインアカウントに存在して、Bedrockのみ別アカウントを使用したいという要件です。
ここで、Kendraを使ったRAGの処理を考えますと、以下のようになります。
- (1) アプリケーションがKendraを使って「Retieve」(検索) を行う
- (2) アプリケーションはKendraの検索結果をプロンプトに埋め込んでBedrockを呼び出して「Generate」(回答生成) を行う
「アプリケーションからKendraへのアクセス」と「アプリケーションからBedrockへのアクセス」が独立していることが分かります。
この中で、アカウントを跨いでアクセスが行われるのは「(2)」のみです。
これは、「Case 1」のパターン「別アカウントのBedrockのLLMを呼び出す」そのものです。
したがって、クロスアカウントを実現する方法も「Case 1」と全く同じです。
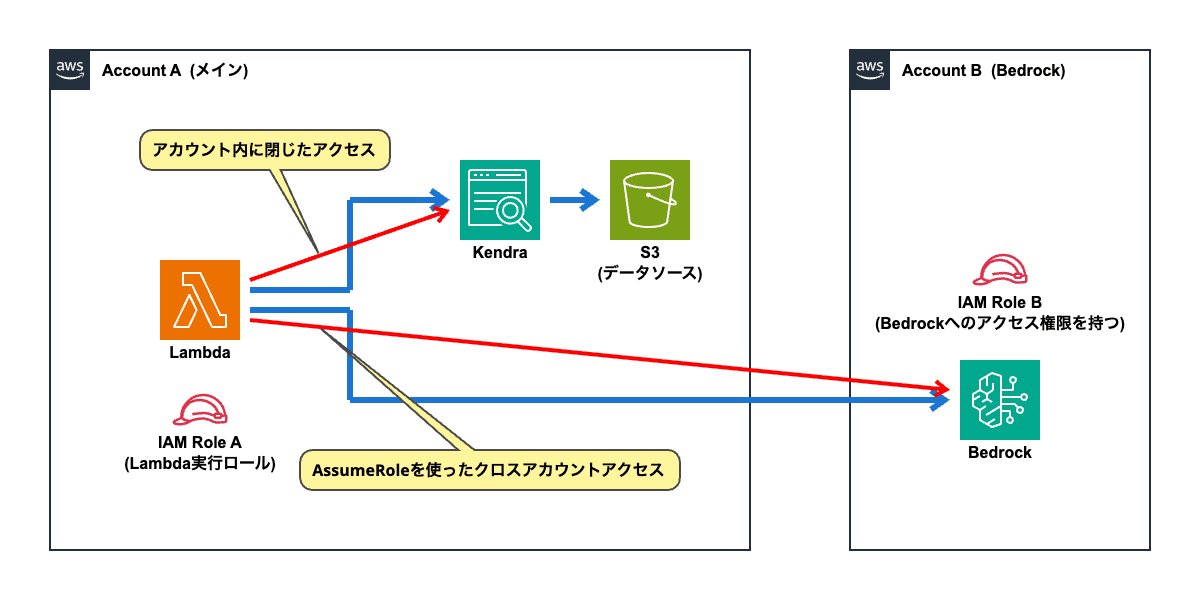
これらを踏まえて、必要な設定を見ていきましょう。
Account B (Bedrock用アカウント) の設定
IAMロールの作成 (Role B)
「Case 1」と全く同じです。
信頼ポリシー:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::{{AccountId_A}}:role/{{Role_A}}"
},
"Action": "sts:AssumeRole"
}
]
}
許可ポリシー:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "bedrock:InvokeModel",
"Resource": [
"arn:aws:bedrock:{{Region}}::foundation-model/{{ModelId}}"
]
}
]
}
Account A (メインアカウント) の設定
IAMロールの作成 (Role A)
信頼ポリシーを以下のように設定します。
「Case 1」と同様です。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
許可ポリシーを以下のように設定します。
ここでは2つのアクセス権限を定義しています。
1つ目は、「Case 1」と同様に「Account B」に対してAssumeRoleを実行する権限です。
2つ目は、自アカウント内のKendraに対してインデックスのクエリを実行する権限です。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "arn:aws:iam::{{AccountId_B}}:role/{{Role_B}}"
},
{
"Effect": "Allow",
"Action": "kendra:Query",
"Resource": "arn:aws:kendra:{{Region}}:{{AccountId_A}}:index/{{KendraIndexId}}"
}
]
}
Lambda関数の作成
KendraとBedrockを組み合わせたRAGを実装します。
import boto3
import json
TARGET_ROLE_ARN='arn:aws:iam::{{AccountId_B}}:role/{{Role_B}}'
KENDRA_INDEX_ID='{{KendraIndexId}}'
def get_session(role_arn, role_session_name):
sts_client = boto3.client('sts')
assumed_role = sts_client.assume_role(
RoleArn=role_arn,
RoleSessionName=role_session_name,
)
session = boto3.session.Session(
aws_access_key_id=assumed_role['Credentials']['AccessKeyId'],
aws_secret_access_key=assumed_role['Credentials']['SecretAccessKey'],
aws_session_token=assumed_role['Credentials']['SessionToken'],
)
return session
def lambda_handler(event, context):
input_text = 'Amazon Kendraはどのようなデータソースコネクタをサポートしていますか?'
kendra_client = boto3.client('kendra')
response = kendra_client.query(
QueryText=input_text,
IndexId=KENDRA_INDEX_ID,
AttributeFilter={
'AndAllFilters': [{
'EqualsTo': {
'Key': '_language_code',
'Value': {'StringValue': 'ja'},
},
}],
},
)
retrieve_results = response['ResultItems'][:10] if response['ResultItems'] else []
session = get_session(TARGET_ROLE_ARN, 'assume-role-session')
bedrock_client = session.client('bedrock-runtime', region_name='ap-northeast-1')
prompt = f'参考情報に基づきユーザーの質問に答えてください。<question>{input_text}</question><reference>{retrieve_results}</reference>'
response = bedrock_client.converse(
modelId='anthropic.claude-3-haiku-20240307-v1:0',
messages=[{
'role': 'user',
'content': [{'text': prompt}],
}],
inferenceConfig={'maxTokens': 1000},
)
print(response['output']['message']['content'][0]['text'])
処理の流れは「Kendraを呼び出して検索」「検索結果をBedrockに与えて回答生成」となっていますが、Kendraの呼び出しが自アカウント内で行われるのに対して、Bedrockの呼び出しはAssumeRoleを使ったクロスアカウントのアクセスになっています。
おわりに
アプリケーションが「別アカウントのBedrockを利用する」パターンとして、主なものをいくつか挙げて、実現方法を解説しました。
AWSにおいてクロスアカウントのアクセスを実現する手法は「AsumeRole」や「リソースベースポリシーの設定」など何通りかあり、それらを選択または組み合わせて実装するとなると、複雑で大変なことに思えるかもしれません。
しかし、全体の構成をパーツ・パーツに分けて考えて行けば、より理解を深めていくことができるのではないでしょうか。
Amazon Bedrockを利用する際に「クロスアカウントのアクセス」が必要になった際は、当ブログエントリが参考になれば幸いです。









